
Bereits bei der Formulierung der konkreten Aufgabenstellung ergaben sich stets neue mögliche Ideen und Vorschläge, die nicht nur maßgeblich den Umfang, sondern auch die Richtung der Software bestimmt haben. Natürlich konnten nicht alle Ideen oder Fragen aufgegriffen werden. Es ist aber wichtig darauf hinzuweisen, dass die erreichte Visualisierung der strukturellen Zusammenhänge der unterschiedlichen Datenbankobjekte noch weiter ausbaufähig ist. Je nach Kontext ist eine anderer Grad der Komplexität und der darzustellenden Dynamik der Daten von Bedeutung.
Die erstellte Anwendung beschränkt sich in der vorliegenden Version auf die Schemaanalyse der Datenbanksysteme Oracle und MySQL. Dabei werden die Oracle-Versionen 9i, 10g und 11g für die Zwecke der Anwendung vollständig unterstützt. Das Plugin für eine MySQL-Datenbank ist in einem experimentellen Zustand und daher nicht vollständig. Durch ein geeignetes Abstraktionslevel lassen sich jederzeit weitere Datenbanksysteme unterstützen. Auch eine individuelle Implementierung aufgrund verschiedener Datenbankdialekte oder spezieller Features ist möglich. Prinzipiell ist jedoch ein JDBC-Treiberplugin für ein entsprechendes Datenbanksystem notwendig.
Für eine geeignete Darstellung der Knoten und Kanten eines Graphen sind weitere Alternativlayouts möglich. Insbesondere die Problematik der sich überschneidenden Kanten kann durch effizientere Algorithmen gelöst werden. Ein Beispiel für solche Algorithmen ist der Algorithmus von Sugiyama zur Minimierung von Kantenschnitten1. Für eine optimalere Darstellung ist auch die Bildung von Clustern, also zusammenhängenden Untermengen, eine mögliche Option.
Das dargestellte Entity-Relationship-Diagramm beinhaltet keine zusätzlichen Informationen wie die Kardinalität, die Optionalität und identifizierende Beziehungen. Die dafür notwendigen Informationen sind bereits durch die Analyse ermittelt worden. Dabei werden die Zwischentabellen von m:n-Beziehungen zu zwei 1:n-Beziehungen aufge- schlüsselt. Nur durch Interpretationen lassen sich echte m:n-Beziehungen nachweisen und anzeigen.
Im Zusammenhang mit der Analyse und Visualisierung der View-Hierarchien sind auch die rekursiven Views interessant. Diese sind zwar als RECURSIVE VIEW bereits im SQL-Standard SQL:1999 vorhanden, allerdings werden sie noch nicht von allen Datenbankherstellern unterstützt. Im Gegensatz zu DB2 von IBM bietet Oracle bisher nur die CONNECT BY-Klausel2 an, die mit komplett anderer Vorangehensweise ähnliche Er- gebnisse liefert. Als Grundlage für die Darstellung rekursiver Viewabhängigkeiten kann die visuelle Veranschaulichung der Triggeraktivitäten dienen.
Bei der Visualisierung der Abhängigkeiten in einer Datenbank gibt es weitere, für diese Anwendung interessante Objekte: Integritätsbedingungen, Assertions, Funktionen, Prozeduren und Typen. Ähnlich wie Trigger enthalten Funktionen und Prozeduren SQL-Code, der sowohl vordefinierte als auch dynamisch zusammengesetzte SQL-Anweisungen enthalten kann. Damit ergeben sich weitere direkte oder indirekte Abhängigkeiten auf andere Objekte in der Datenbank. Auch die Aufschlüsselung einer objektrelationalen Typhierarchie kann in Erwägung gezogen werden.
Im Rahmen dieser Arbeit wird nur eine statische Analyse der Objekte und deren Abhängigkeiten verfolgt. Eine tiefergehende Untersuchtung der Abhängigkeiten kann durch die Betrachtung der spaltenbezogenen ON-Klausel oder der Bedingungsklausel WHEN in PL/SQL-Triggern ermöglicht werden.
Eine andere visuelle Darstellungsmöglichkeit, eventuell auch dreidimensional, wäre, die Tabellen mehr in das Zentrum der Betrachtung zu stellen. Dabei würden alle drei Ansichten der Anwendung – Views, Trigger und das ERD mit Fremdschlüsseln – vereinigt und bei Bedarf im Graphen jeweils zu den Tabellenobjekten auf unterschiedliche Weise angezeigt.
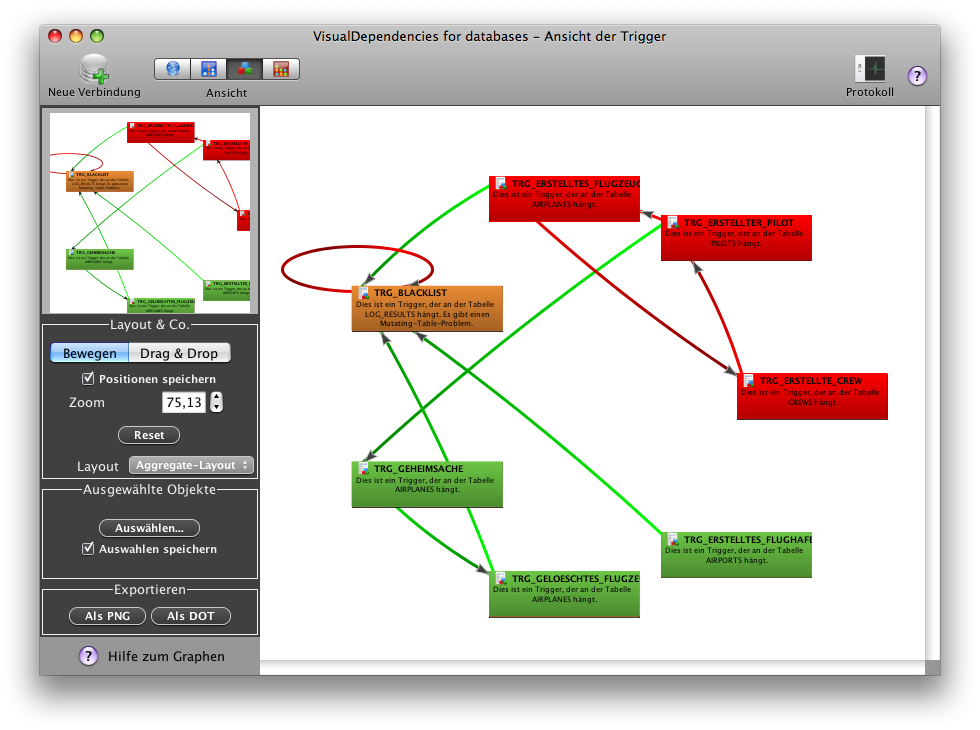
vdb: Mutating-Table-Trigger
Als einen zusätzlichen Ansatz zur Visualisierung könnte die Darstellung eines dynamischen Kontrollflusses dienen. Ähnlich wie in einem UML-Aktivitätsdiagramm zeigt das Kontrollflussdiagramm einzelne Aktivitäten und Kontrollflüsse an. Dabei sind die Aktivitäten die einzelnen Objekte der Datenbank und die Kontrollflüsse resultieren aus den Abhängigkeiten. Damit ergibt sich ein weiteres und interessantes Anwendungsszenario. Nach der Spezifizierung einer DML-Anweisung durch den Benutzer zeigt die Visualisierung die einzelnen Kontrollflüsse durch alle benutzten und verwendeten Datenbankobjekte mit den entsprechend konkreten Daten und Entscheidungen an. Diese teils indirekten Implikationen, beispielsweise auch kaskadierendes Löschen bei Integritätsbedingungen, können somit ebenfalls in einem Graphen dargestellt werden. Dafür ist es allerdings notwendig, dass der Parser den Inhalt des Triggerkörpers komplett einliest und verarbeitet. Für dynamische Kontrollflüsse sind alle Blöcke (Compoundtrigger, Bedingungen, Schleifen) notwendig zu betrachten und bei Ausführung auszuwerten.
Mit Hilfe dieser Software – und unter Berücksichtigung der möglichen Erweiterungen – gibt es nun ein hilfreiches Werkzeug, um die direkten und indirekten Abhängigkeiten von Objekten in einem Datenbanksystem sowohl zu erkennen als auch grafisch darzustellen. Durch eine flexible und erweiterbare Architektur ist das Softwareprodukt auch für neue Anforderungen gut einzusetzen.
Dieser Text entstammt aus der abgegebenen Diplomarbeit, Kapitel “Ausblick”, und wurde für das Web link-technisch aufgewertet.
Bild-Quelle: https://en.wikipedia.org/wiki/File:Sydney_Harbour_Bridge_night.jpg
{kind=link}
Für weitere Informationen zu Graphenlayouts: http://ftp.informatik.uni-stuttgart.de/iste/ps/Lehre/S_Graphen/kopp.pdf (ebenfalls im Literaturverzeichnis). ↩︎
Oracle nur in Verbindung mit einer rekursiven Select-Abfrage möglich. ↩︎